
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 튜플
- lambda
- 채팅
- 파이썬
- node
- dict
- docker
- 카톡
- TypeScript
- merge
- crud
- SAA
- MongoDB
- git
- EC2
- RDS
- wetube
- async
- AWS
- flask
- Props
- S3
- Vue
- 중급파이썬
- socket io
- SSA
- react
- pandas
- NeXT
- Class
- Today
- Total
초보 개발자
RDS최적화 기록일기 본문
배경 상황
RDS MySQL을 사용하고 있었고 1개의 primary와 3개의 read replica가 있었다. 각 replica의 스펙은 m5.12xlarge이었으며, RAM이 192GB, vCPU가 48이다. 상당히 고스펙의 데이터베이스라고 할 수 있다. Database에 자사 상품의 정보가 담겨있고,
Agent가 API를 요청하면 server에서 해당 API내용에 맞는 쿼리를 RDS로 요청 후 리턴하는 구조이다. 따라서 Insert update보다는 select 쿼리가 압도적인 비중을 차지한다. QPS기준으로 하루에 300정도를 유지했으며, read replica가 3개이므로 각 데이터 베이스가 100을 부담한다고 생각했다.

RDS이 과다 프로비저닝 된 것이라고 생각을 했는데, CPU를 보니 평균 70~80%를 유지하고 있었다. 무언가 문제는 있다고 생각했지만 특정할 수는 없었고 요청하는 쿼리가 복잡해서 그런가 하며 넘겼다. 아래는 CPU사용률을 나타내는 그래프이다.

또 6개의 RDS의 스토리지의 타입이 IO1으로 설정이 되어있었고, 프로비저닝 IOPS가 50,00에서 10,000까지 설정이 되어있었다. 이로인해 매달 러닝코스트가 IOPS값으로만 $3,600달러가 청구되었다.
문제점
나는 2개의 의문을 가지고 있었다.
1. RDS의 36xlarege에 해당하는 RDS 스펙이 저렇게 유지되고있는 현상이 맞는것인가?
2. 매 달 IOPS비용으로만 $3,600달러를 지불하는게 맞는것인가?

2번 해결 과정
2번에 대한 대답으로, 나는 아니다 라고 생각을 했다. 따라서 찾아보았다.
IOPS
Read IOPS를 확인해보니 거의 0에 수렴하였다. 우린 5,000~ 10,000으로 설정을 했는데 말이다.
Write IOPS는 200~300정도를 유지하고 있었다. 이 부분을 보고 분명히 문제가 있다고 인지했다.
확인해본 결과,
Database 의 기본적인 흐름으로서 SQL 로 읽은 데이터등은 메모리상에 전개된다.
그 후의 처리도 기본적으로는 메모리상에서 조작을 실시한다.
메모리상에 없는 데이터나 넘쳤을 경우에 스토리지의 읽고 쓰기가 발생한다.
그 때문에, 스토리지 I/O가 별로 발생하고 있지 않다고 하는 것은,
메모리상에서 처리가 완결되어 있거나 혹은, 스토리지에서 읽는 데이터량이 적을 것으로 생각된다.
덧붙여 Database 의 동작으로서 스토리지 I/O 가 많은 것은,
메모리가 부족한 경우가 많기 때문에 처리가 느려지는 경향이 있다.
그래서 스토리지의 I/O가 적은 것이 좋다.
이와 같은 답을 얻을 수 있었다.
즉 IOPS가 발생하지 않는다는것은 메모리 상 데이터가 전부 들어있다는 뜻으로 이해할 수 있다.
-> RAM이 상당히 높다, 이에 따른 IOPS가 필요하지 않다. 이렇게 생각할 수 있다는 것이다.
따라서 현재의 스펙에서 Read IOPS가 발생하지 않는 이유를 이해할 수 있었고,
Replica에서도 write IOPS의 수치가 존재하는 것은 복제가 발생할 때 생기는 것 또한 이해할 수 있었다.
스토리지
IO1은 어떤 스토리지 타입인지, IOPS는 어떤역할을 하는 것인지, 기저에 IO와 GP에서 사용하는 IOPS는 서로 다르다라고 생각했던 부분을 바로잡는 데, 그리고 GP2에서 GP3로, GP3에서 IO1으로의 마이그레이션은 많았지만, 반대로 IO1에서 GP3로는 없었다. 때문에 찾는 데 시간이 정말 오래걸렸다.
2023.05.24 - [AWS] - AWS IO vs GP3 storage
GP와 IO의 다른 점은 IO는 미션크리티컬한 성능에 어울리며 IOPS를 GP에 비해 4 ~ 24배 이상 사용할 수 있는 부분, 볼륨의 사이즈도 4 ~ 24배 사용할 수 있다는 점이다. 현재 상황에서 IO타입을 고집할 이유가 전혀 없었다. IO에서 사용하는 IOPS와 GP에서 사용하는 IOPS의 가격차이는 어마무시하다.
당장 스토리지를 바꾸고 싶었지만, 다운타임이 생기면 안되기에, 그리고 타입과 IOPS를 변경해도 문제가 없는지에 대해서 자세히 확인해볼 필요가 있었다.
IOPS를 변경해도 반영바로 되며 다운타임이 생기는 것이 없다는 것을 확인했다.
하지만 앞서 말했다싶이 IO에서 GP3로 마이그레이션의 정보가 없어서 쉽게 확인할 수 없었지만, 수 많은 구글링을 통하여, 타입 변경으로 인한 다운타임이 생기지 않고, 데이터에도 문제가 생기지 않는 다는 것을 확인했다.
따라서 GP3, IOPS12,000 으로 문제 없이 변경하였고. (EBS 사이즈가 400GB이상이면 스루풋, IOPS의 기본값 이상으로 설정해야하기에 어쩔 수 없이 12,000으로 하였으나 가격은 정말 저렴해졌다.)
성능은 오히려 좋아졌다고 봐야하지만 러닝코스트는 $3,600달러 감소를 시킬 수 있었다.
1번 해결 과정
메모리
의문의 확장은 여기서 시작이 되었다.
CPU는 항상 70%~80%를 유지하고있는데
freeable memory는 말도안되게 높다. 이건 뭔가 단단히 문제가 있는 것이다.

이로 인해서 확인해본 결과 쿼리에서 INDEX가 효율적으로 사용되고 있지 않을 것이라는 답변을 받았다.
그래서 메모리가 아닌 CPU가 많이 소비되고 있다는 것이다.
이렇게 메모리가 많이 남아, innodb_buffer_pool_size에 할당이 제대로 되어있지는 않은것인가를 확인했는데, 75%가 할당이 되어있었다. CPU나 데이터 베이스 부하가 높다는점, SQL 실행시간이 길다는 점을 고려하면 SQL에서 INDEX가 제대로 이용되지 않고있는 것 같다. SQL 튜닝으로 부하를 낮출 수 있다. 퍼포먼스 인사이트에서 확인할 수 있다.
상위의 쿼리를 손보라고 한다.

INDEX튜닝을 하지도 않았다. 다만 쿼리 내용을 손 보았을 뿐이다. 복잡한 구문으로 이루어 진 것을 효율적으로 말이다.
그리고 상위 3개 중 제일 위에있는 것 하나만 바꾸었는데 아래와 같은 효과를 보였다.

쿼리속도가 1초정도가 걸리던 것이, 0초에 가깝게 바뀌었다.
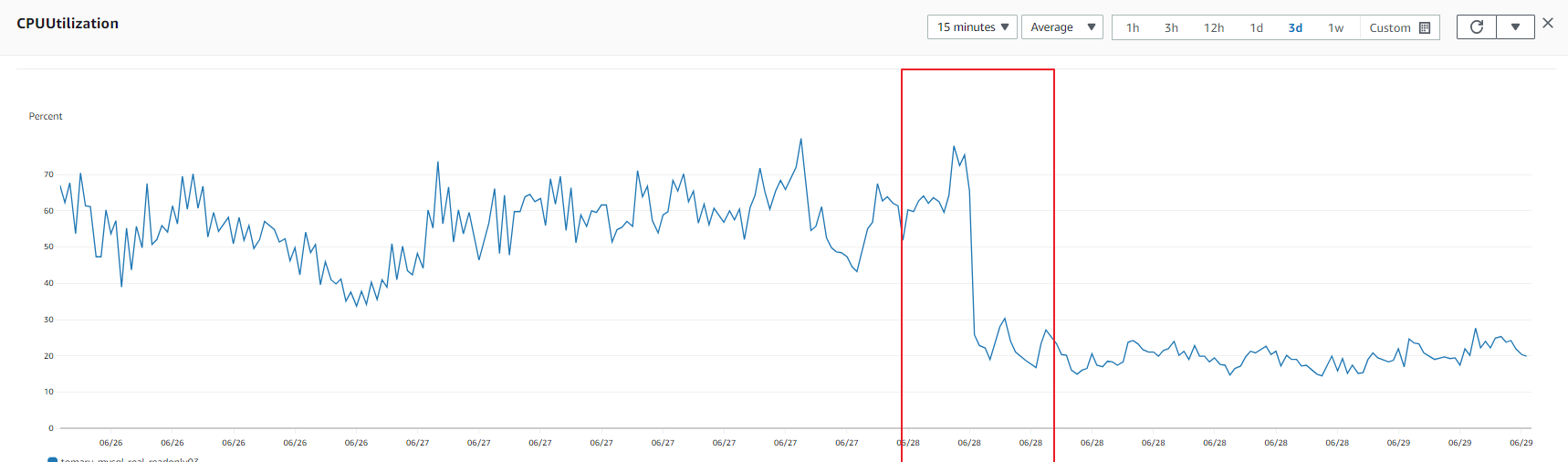

..? 왜 지금까지 read replica에 36xlarge나 사용하고있던걸까.. CPU만 보고 판단을 해서는 절대 안된다.
다만 확실한 것은 있다.
현재 시스템에서, 대다수의 RAM은 사용이 되지 않고있고, 쿼리의 비효율성으로 인한 데이터베이스 부하가 발생하고있었다는 사실이다.
이로 인해 RI계약에서 단순 계산만해도 3분의1까지 줄여도 문제가 없을 것같다. 억단위에 해당하는 돈이다.
시스템에 문제가 있다고 판단해서 고액의 코스트를 삭감할 수 있었다. 스킬이 필요했던 것도아니다. 단순히 기본적인 의문점의 꼬리를 물고갔기 때문이다. 그리고 답은 정말 기본적인 것에 있었다.
현재 RAM이 너무 많이 방치되고있는점, Freeable, Free, Active, Inactive, Buffer Memory등의 역할을 공부해야해야한다.
다만 램을 거의 안쓴다고해서 스펙을 줄여버리면 CPU마저 줄기에 이 부분도 생각해야 할 것이다.
성과를 냈지만 어디가서도 자랑하지 못할 것이다. 오히려 이상하게 볼 것이다.
이러한 시스템이 지금까지 방치되고있었던 걸 몰랐었나?
이건 정말 기본적인것 아닌가?
이런 질문을 받으면 나는 사실 할말이 없어지기 때문이다.
여기서 느낀점은 두가지가 있다.
1. 기본을 모르면 이렇게까지 비효율적일 수 있다.
2. 관련지식을 가진 사람이 부재하면 이렇게까지 방치될 수도있구나.