
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- EC2
- dict
- 채팅
- wetube
- MongoDB
- async
- Class
- S3
- lambda
- 파이썬
- pandas
- crud
- RDS
- docker
- TypeScript
- Vue
- 튜플
- 카톡
- git
- node
- SSA
- merge
- 중급파이썬
- flask
- react
- Props
- SAA
- NeXT
- socket io
- AWS
- Today
- Total
초보 개발자
EC2 Batch에서 Lambda로 변경 본문
EC2 Instance 에서 Lambda로 변경하려는 이유
24/7 EC2 Instance를 굳이 사용할 이유가 있을까 싶었다. 저렴한 EC2스펙을 사용하고 있어 연간 비용이 얼마 들지 않는다 하더라도 단순히 배치 소스코드만 돌릴 뿐이어서, 람다로 실행시킨다면 좀 더 효율적으로 관리할 수 있을 것이라는 생각이 들었다.
t2.midium 10개 , 3년 RI계약시 개당 687달러 ,
$ 6,870 per 3 years
lambda 2GB ram 0.0000000333 per seconds , 한달에 4320번 호출, 한번에 배치 서버마다 다르지만 2~8초 소요 (7초로 잡음), 한달 약 $11 10개돌릴 경우
$3,960달러 per 3 years + NAT gateway + 1,607 = 5,567 3 years
NAT gate way가격을 빼면 약 3000달러~, 연간 1000 달러~ 정도를 절약할 수 있게 된다.
변경 전
1. 소스코드를 war 파일로 빌드
2. war 파일을 tomcat으로 카피
3. 톰캣 실행
4. 스프링 부트에 의해서 자동으로 10분에 한번씩 배치 코드를 실행시킴
EC2 인스턴스에서 10분 마다 배치를 돌려서 거래처의 API에 요청을 한 뒤 변경 점이 있다면 회사 RDS를 update시킨다.
변경 후
2. 도커 이미지로 빌드
3. 도커 이미지를 AWS ECR에 업로드
4. 람다에 이미지를 넣음 ( 혹은 변경시, 기존 것을 변경 )
5. 람다가 aws resource ( RDS, Cloud watch ... )에 접근할 수 있도록 , 인터넷에 접속할 수 있도록 설정
6. 이벤트 브릿지 생성하여 배치를 돌림
7. 로그, 실패 로그를 기록

로그 기록
로그는 cloudwatch log를 사용하려고 한다. cloudwatch log는 5gb까지는 무료로 저장할 수 있기에 3~4gb까지만 저장하고 ( 대략 일주일 ) 일주일이 지난 로그는 s3에 저장을 시킨다. s3에 저장을 시키고 90일이 지난 로그는 삭제를 시키는 기능을 만들었다.
람다를 생성하고, eventBridge를 작동시켜 하루에 한번 되도록 하였다. 람다를 VPC에 넣어주는 작업은 하지 않았고(NAT를 사용할 필요가 없기 때문), s3와 cloudwatch에 접근할 수 있도록 IAM롤을 부착시켜주었다.

코드는 파이썬으로 작성하였다.
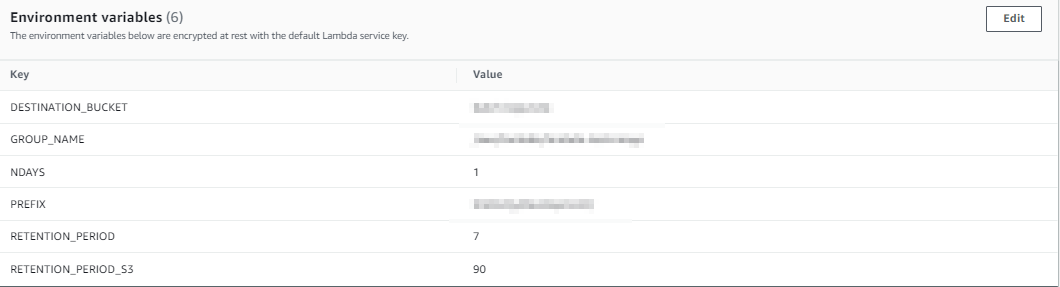
NDAYS가 하루치의 cloud watch log 양을 기록, ( 1 day ) 람다 작동시점으로 계산 , 람다 작동은 00:00분에 시작시킴.
RETENTION_PERIOD는 cloudwatch log내에서 보유하는 기간, 일주일 치만 저장해놓음 그 이외엔 삭제시킴
RETENTION_PERIOD_S3 는 s3에서 보유하는 기간 90일이 지나면 삭제 시킴
import boto3
import os
import datetime
import logging
import time
GROUP_NAME = os.environ['GROUP_NAME']
DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET']
PREFIX = os.environ['PREFIX']
NDAYS = os.environ['NDAYS']
nDays = int(NDAYS)
RETENTION_PERIOD = os.environ.get('RETENTION_PERIOD')
RETENTION_PERIOD_S3 = os.environ.get('RETENTION_PERIOD_S3')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logs = boto3.client('logs')
def lambda_handler(event, context):
exportLogsToS3()
deleteCloudwatchLogs()
deleteObjectsInS3()
def deleteCloudwatchLogs():
# start delete logs in cloudwatch logs
logger.info('【Start】delete logs except within 7days')
# start time is set 00:00:00
startup_date = datetime.datetime.today().replace(
hour=0, minute=0, second=0, microsecond=0
)
deletion_date = startup_date - \
datetime.timedelta(days=int(RETENTION_PERIOD))
logger.info('retain period :%s', deletion_date)
# to make sure to use same time format with lastEventTimestamp
global deletion_timestamp
deletion_timestamp = int(deletion_date.timestamp() * 1000)
# the logs which wiil be deleted
try :
target_streams = find_target_streams(next_token=None)
logger.info('count of logs:%d', len(target_streams))
# delete
for stream in target_streams:
# logger.info('log :%s', stream['logStreamName'])
logs.delete_log_stream(
logGroupName=GROUP_NAME,
logStreamName=stream['logStreamName']
)
logger.info('【Conmplete】delete logs except within 7days')
except :
logger.error("ERROR from deleteCloudwatchLogs func")
def find_target_streams(next_token: str) -> list:
"""
get logs throughout describe_log_streams(Max50/per)
delete logs that meets condition
--------
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/logs.html#CloudWatchLogs.Client.describe_log_streams
"""
def is_target_stream(stream):
return stream.get('lastEventTimestamp') < deletion_timestamp
if next_token is None:
describe_response = logs.describe_log_streams(
logGroupName=GROUP_NAME,
orderBy='LastEventTime'
)
else:
describe_response = logs.describe_log_streams(
logGroupName=GROUP_NAME,
orderBy='LastEventTime',
nextToken=next_token
)
itr_streams = filter(is_target_stream, describe_response['logStreams'])
target_streams = list(itr_streams)
if 'nextToken' not in describe_response:
return target_streams
time.sleep(0.3)
target_streams.extend(find_target_streams(describe_response['nextToken']))
return target_streams
def deleteObjectsInS3():
now = datetime.datetime.now()
retention_period_s3 = int(RETENTION_PERIOD_S3)
the_day_before = now - datetime.timedelta(days=retention_period_s3+1)
try:
logger.info('【Start】delete logs in S3 %s ',the_day_before)
s3 = boto3.resource('s3')
bucket = s3.Bucket('batch-logs-test')
target_folder = os.path.join(PREFIX, the_day_before.strftime('%Y{0}%m{0}%d').format(os.path.sep))
bucket.objects.filter(Prefix=target_folder).delete()
logger.info('delete %s ',target_folder)
logger.info('【Complete】delete logs in S3 %s ',the_day_before)
except :
logger.error("ERROR from deleteObjectsInS3 func")
def exportLogsToS3():
currentTime = datetime.datetime.now()
startDate = currentTime - datetime.timedelta(days=nDays)
endDate = currentTime - datetime.timedelta(days=nDays - 1)
fromDate = int(startDate.timestamp() * 1000 )
toDate = int(endDate.timestamp() * 1000 )
BUCKET_PREFIX = os.path.join(PREFIX, startDate.strftime('%Y{0}%m{0}%d').format(os.path.sep))
try:
logger.info('【Start】Export Today Logs to S3')
client = boto3.client('logs')
logger.info('export between %s ~ %s logs to s3',startDate,endDate)
client.create_export_task(
logGroupName=GROUP_NAME,
fromTime=fromDate,
to=toDate,
destination=DESTINATION_BUCKET,
destinationPrefix=BUCKET_PREFIX
)
logger.info('【Conmplete】Export Today Logs to S3')
except :
logger.error("ERROR from exportLogsToS3 func")
잘 동작하는 걸 확인할 수 있음.
느낀 점
기존에 있던 batch용 ec2 server를 없애고 lambda를 사용하여 대체하였다. 시간이 생각보다 걸렸다. 예상치 못했던 부분들이 생겨났기 때문이다. 하지만 개발자 분들과 열심히 소통하며 하나하나 해결해나갔으며 결과적으로 잘 동작하는 batch labmda를 만들 수 있었다. 이 과정에서 많은 것을 배울 수 있었던 것 같다.
시행착오
Lambda source code issue
Jar file 250MB issue
처음에 스프링 소스코드를 jar 파일로 만든 후 s3에 업로드하여 람다에서 그 jar을 실행시키려고 하였으나,
unzip된 jar파일의 size가 250MB를 초과하면 람다에서 실행시킬 수 없었다. 이에 대한 해결책으로 node js는 모듈을 분리하여 모듈은 레이어에 올리고 소스코드는 람다에 올려서 사용하는 식으로 가능해보였지만, Spring특성상 모듈을 분리할 수 없다고 하기에 일단락 지었다.
CloudFormation 사용
CloudFormation을 사용하여 람다를 만들면 혹시 가능할 수도 있지 않을까 라는 생각에 ( 결국 s3에서 jar파일 받아오는 건 변함 없지만 일단 해봄 ) AWS SAM을 통해 CloudFormation으로 시도 하였지만 똑같은 250MB 이슈로 실패
docker image 사용
docker image를 사용하면 10GB까지 가능하다는 생각에 가능할 것이라는 확신을 가지고 시도.
dockerfile을 작성하여 image를 빌드 하고 ECR에 업로드 하였다. 이 후 이 도커이미지 파일을 람다에 업로드하여 실행하니 잘 작동함.
spring version issue
람다에서 사용하는 Spring의 module버전은 2.X대를 사용하는데, 우리가 사용하고 있던 Spring module버전은 1.X대였다. 따라서 우리의 코드로 람다를 실행시켰을 때 아래와 같은 오류가 발생하였다.
java.lang.NoClassDefFoundError: org/springframework/boot/WebApplicationTypeAWS Lambda SDK의 LambdaContainerHandlerClass를 상속 후 2.X버전을 사용하는 것이 아닌 1.X대 버전을 사용하도록 커스터마이징하여 문제를 해결하였다.
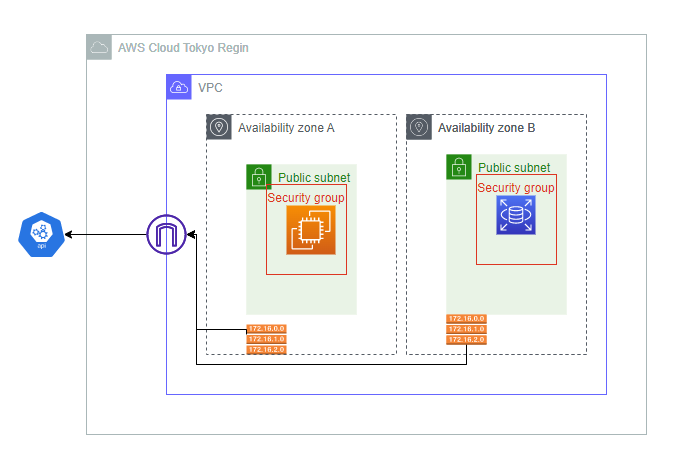
can't access Internet from lambda in public subnet
we have to use NAT Gateway or NAT instance
현재 회사의 Sunbet이 전부 public subnet으로 구성되어있는 상태이다. 따라서 lambda를 생성할 때 지정한 subnet도 public이기에 기본적으로 IGW를 타고 인터넷 통신이 가능할 것이라는 안일한 생각을했음.
처음에 안되길래 보안그룹 문제인가보다 하고 인바운드 규칙에 동적 포트, every IP를 개방했지만 역시 통신 불가. (유지)
삽질을 거쳐 문제의 원인을 파악
public 서브넷에 연결된 함수는 일반적으로 internet access 불가. 그 이유는 lambda는 public IP를 가질 수 없기 때문에 IGW에서 트래픽이 막힘. 아래와 같이 변경 후 성공적으로 인터넷 통신 가능
1. private subnet에 람다를 배치,
2. public subnet에 NAT gateway 혹은 NAT instance를 배치,
3. route table을 생성하고 명시적으로 private subnet 선언, 로컬 이외의 트래픽은 NAT gateway로 전송하도록 설정.
4. lambda의 VPC를 public이 아닌 private subnet으로 변경.
'AWS' 카테고리의 다른 글
| AWS RDS 적절한 instances 고르는 방법. (1) | 2023.04.22 |
|---|---|
| S3, Lambda, Cloud Watch $7,000달러 과금 및 예방 대책 (0) | 2023.04.21 |
| AWS 요금 개선 (0) | 2023.04.14 |
| EC2, RDS Reserved Instance 크기 조절 가능 (0) | 2023.04.14 |
| EC2 Status check failed시 자동으로 재부팅 하는 방법 (0) | 2023.04.11 |



